

AIが描く絵
見分けられる?
画像生成AIはノイズから絵を描く
言葉を入力すると精巧な画像を作る「画像生成AI(人工知能)」が注目を集めています。英スタートアップが開発した「Stable Diffusion(ステーブル・ディフュージョン)」など精巧なAIが相次ぎ無料公開され、日本語版も登場しました。AIはどんな仕組みで画像を生み出すのでしょうか。AIが描いた絵と人間が描いた絵や写真を比べながら、クイズとビジュアルで解説します。
日経電子版の「Data Finder」のコーナーでも、データ分析をもとに画像生成AIの最新トレンドを追った記事「絵を描くAI 発信地は日本」を公開しています。
TOPIC1
いくつ分かる?
AIと人間の絵をクイズで比較
人間が描いた絵とAIの描いた絵を見分けることはできるのでしょうか。同じモチーフの画像2枚から、AIの絵を見分けるクイズに挑戦してみましょう。各問の解説ではAI画像の特徴も紹介します。
クイズで登場した「AIの絵」は画像生成AI「Stable Diffusion」を使って生成しました。1つのモデルで浮世絵やイラスト、写真など様々な絵柄を作れるのがAIの強みです。
人間の絵と見分けがつかない精巧な画像がある一方、常識外れの画像を出力することもあります。AIは人間社会が作り出した膨大な絵や写真から画像の特徴を学習しますが、社会の常識を学んでいるわけではないからです。
TOPIC2
AIが絵を描く仕組み
「生成」と「学習」の過程をビジュアル解説
AIはどうやって絵を描いているのでしょうか。画像生成と学習の仕組みを知れば、AIと人間がうまく付き合うヒントが見つかるかもしれません。AI開発のrinna社(りんな、東京・渋谷)の応用科学者、シーン誠さんの監修で、言葉から画像を作り出す技術を画像生成AI「Stable Diffusion」の論文をもとに図解します。
AIは画像の「切り貼り」を
しているわけではない

誤解されがちですが、画像生成AIは既存の絵などを組み合わせて画像を加工しているわけではありません。AIは膨大な量の画像をもとに絵の描き方を学習し、言葉や画像の処理技術を使って画像を新たに生成します。
ノイズが消えていく
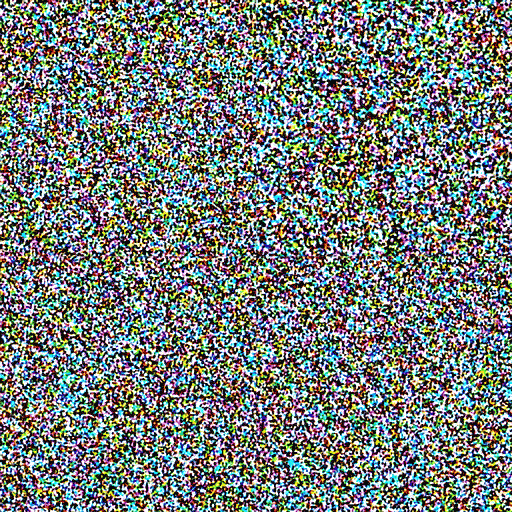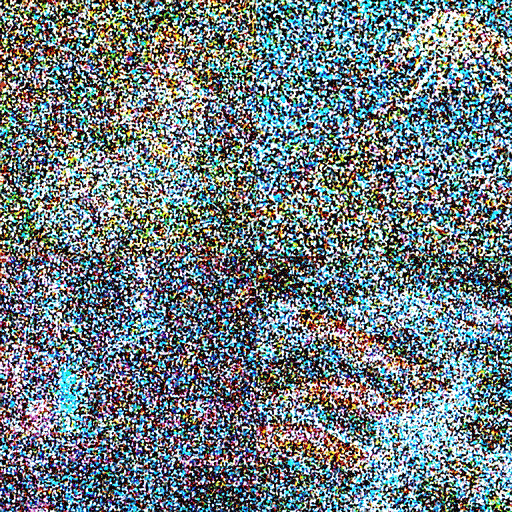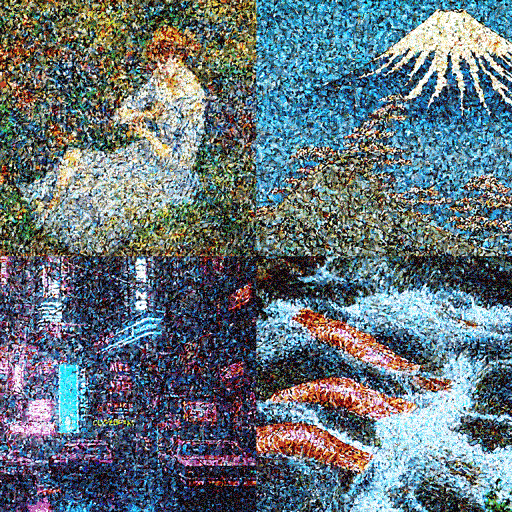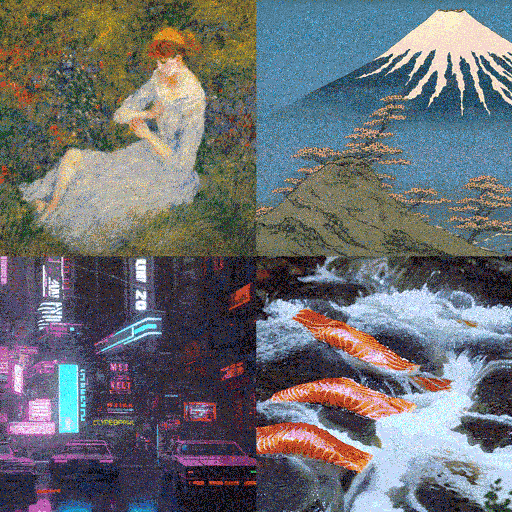
画像を生成する
3つのステップ

AIが画像を生成するステップは大きく3つに分かれています。1つめは「テキスト変換」。入力した言葉をAIが解釈しやすい概念に変えます。2つめは「画像データの生成」。完全に特徴のないノイズだけの画像からノイズを少しずつ取り除きながら、テキストに関連した画像に近づけていきます。3つめは「復号」。コンピューターが短時間で計算できるように圧縮していた画像データを人間の目で見やすいかたちに戻し、画像を出力します。
1:入力した言葉を変換する

画像生成AIの最大の魅力のひとつは好きな言葉を入力して画像を作れることです。入力する言葉は「プロンプト」「呪文」と呼ばれています。画像生成の1つめのステップでは、人間が入力した呪文を「ベクトル」と呼ばれるAIが解釈しやすい数値化された概念に変換します。例えば「猫」のベクトルを用いると、AIが猫の画像の特徴を素早く見つけることができるようになります。
2:ノイズを取り除く

2つめのステップでは画像のデータを作成します。人間が真っ白なキャンバスに絵を描くのに対し、AIはランダムなデータを詰め込んだ純粋なノイズ画像から絵を描きます。画像から少しずつノイズを取り除く作業を何度も繰り返し、1つめのステップで変換した言葉に従った画像を完成させます。
ノイズを消して
キーワードに近づける

ノイズを取り除く過程では画像をキーワードに近づける処理をしています。AI内部の広大な言葉の地図上で、1つめのステップで作られた言葉の概念を目的地として設定します。どうやってノイズを消せば言葉の概念により近い画像ができるかを推定しながら、画像を少しずつ目的地に近づけていきます。
3:人間が見やすい画像に復号

3つめのステップでは、1つめと2つめのステップで作った画像データを人間の目で見やすい画像に復号して出力します。ビジュアル解説では人間の目に見やすい画像を使って説明しましたが、実際にAIが処理するのは「潜在空間」と呼ばれる機械の認識できる空間で小さく圧縮した画像です。小さい画像を使うことでいわば「時短」で絵を描くことが可能になり、高性能なコンピューターなら言葉を入力してからわずか数秒で画像を作れるのです。最後に圧縮したデータを色や幅、高さからなる画像に戻し、完成品ができあがります。
AIは「逆方向」に学習する

AIが画像生成のために消すべきノイズを判断できるのは、ノイズのある絵とない絵の違いを学習しているからです。学習の過程ではまず、生成の過程とは「逆方向」にきれいな絵や写真に様々なノイズを人工的に加えます。
次に、ノイズを加えた画像からノイズを加える前の画像を生成できるように訓練します。膨大な量の画像をもとに訓練を繰り返し、純粋なノイズ画像からもきれいな画像を作れるようになるのです。
こうしたAIの仕組みを「拡散(Diffusion)モデル」と呼びます。「Stable Diffusion」は学習済みのモデルとして公開されていますが、ほかの人が追加学習させた派生モデルなども登場しています。
学習のカギは「量」と「質」

AIが精巧な画像を生成するには、量と質を兼ね備えた学習データが欠かせません。例えば「Stable Diffusion」はインターネット上で収集した画像と説明テキストを大量に収容した大規模なデータセットから約23億枚の画像を学習しています。世界最大級の美術館である米メトロポリタン美術館の収蔵品は200万点あまり。AIはその1000倍以上のデータから画像の特徴を学んでいるのです。

人間が良質な絵画に触れて審美眼を養うように、AIも質の高いデータによる訓練が必要です。学習に使う画像と説明テキストの整合性が取れていなかったり、画質が粗かったり、内容が偏っていたりすると正しい予測はできません。
TOPIC3
好みの画像を作ってみよう
AIを擬似体験
「パリ」「京都」「夕方」「浮世絵」など10個のキーワードから好きな言葉を選んで、画像を作ってみましょう。キーワードはいくつ選択しても構いません。
実際のAIでは自由に言葉を入力できますが、ここではあらかじめ用意した言葉から1023通りの画像を準備しました。
画像の下のキーワードを選択
2022年8月に画像生成AI「Stable Diffusion」が誰でも無償で利用できるオープンソースで公開され、画像生成AIの技術革新は驚くほどの速さで進むようになりました。画像生成AIは学習データや仕組みによって独特の癖があります。人類が築き上げてきた絵画史がすべて詰め込まれたかのような精巧な絵に息をのむ一方で、ちょっと常識外れな画像が生成されて思わず笑ってしまうこともあるかもしれません。
AIが「絵を描く」という人間の根源的な創作活動に踏み込んできたことに不安を感じる人もいるでしょう。ただ、技術革新が人間の創造の世界を広げた例はたくさんあります。19世紀に誕生した写真の技術は印象派の絵画が生まれる大きなきっかけになりました。チェスや将棋の世界ではAIを使った研究で新しいスタイルに挑む藤井聡太五冠のようなハイブリッド型のプレーヤーが活躍しています。
いま私たちに求められるのは、AIの仕組みを正しく理解したうえで、人間とAIが共存する青写真を描いていくことでしょう。
データから最新トレンドを探るコーナー「Data Finder」でも画像生成AIをめぐる世の中の動きについて解説します。
 絵を描くAI
絵を描くAI発信地は日本 2022.12.4
関連記事
AIが生成した画像の著作権や「Stable Diffusion」については、こちらの記事をご参照下さい。
注釈
クイズ、ビジュアル解説、画像生成体験で「AIが生成した画像」として掲載した絵は日本経済新聞社の研究開発組織、日経イノベーション・ラボの協力のもと、画像生成AI「Stable Diffusion」で生成しました。使用したのはバージョン1.4と2.0の学習済みモデルで、追加学習はしていません。実際の呪文は英語ですが、記事中では日本語訳で紹介しています。
画像生成体験で使った10個のキーワードはジョージア工科大学の研究チームがまとめた約1400万件の呪文と画像のデータベースのテキスト分析を行い、使用頻度の高い単語を参考に抽出しました。実際のプロンプトは英語ですが、記事中では日本語訳で紹介しています。
画像生成に使った主なプログラムはGitHub上でご覧いただけます。好きな呪文を入力すれば、本記事のようなAI画像を生成したり、生成過程のアニメーションを作成したりできます。
ビジュアル解説は「Stable Diffusion」の仕組みについて書かれた独ミュンヘン大学の研究者らの論文をもとに、rinna社の監修で作成しました。